
Re: [tsvwg] Todays Meeting material for RTT-independence in TCP Prague
Sebastian Moeller <moeller0@gmx.de> Thu, 27 February 2020 13:26 UTC
Return-Path: <moeller0@gmx.de>
X-Original-To: tsvwg@ietfa.amsl.com
Delivered-To: tsvwg@ietfa.amsl.com
Received: from localhost (localhost [127.0.0.1]) by ietfa.amsl.com (Postfix) with ESMTP id 515C43A08F3 for <tsvwg@ietfa.amsl.com>; Thu, 27 Feb 2020 05:26:58 -0800 (PST)
X-Virus-Scanned: amavisd-new at amsl.com
X-Spam-Flag: NO
X-Spam-Score: -1.647
X-Spam-Level:
X-Spam-Status: No, score=-1.647 tagged_above=-999 required=5 tests=[BAYES_00=-1.9, DKIM_SIGNED=0.1, DKIM_VALID=-0.1, FREEMAIL_ENVFROM_END_DIGIT=0.25, FREEMAIL_FROM=0.001, RCVD_IN_DNSWL_BLOCKED=0.001, SPF_HELO_NONE=0.001, SPF_PASS=-0.001, URIBL_BLOCKED=0.001] autolearn=no autolearn_force=no
Authentication-Results: ietfa.amsl.com (amavisd-new); dkim=pass (1024-bit key) header.d=gmx.net
Received: from mail.ietf.org ([4.31.198.44]) by localhost (ietfa.amsl.com [127.0.0.1]) (amavisd-new, port 10024) with ESMTP id R_tubM0zUWLF for <tsvwg@ietfa.amsl.com>; Thu, 27 Feb 2020 05:26:54 -0800 (PST)
Received: from mout.gmx.net (mout.gmx.net [212.227.15.19]) (using TLSv1.2 with cipher ECDHE-RSA-AES128-GCM-SHA256 (128/128 bits)) (No client certificate requested) by ietfa.amsl.com (Postfix) with ESMTPS id B93193A08DD for <tsvwg@ietf.org>; Thu, 27 Feb 2020 05:26:53 -0800 (PST)
DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/simple; d=gmx.net; s=badeba3b8450; t=1582809965; bh=D4QNH1forlWJYOeLdSlibkQ25/be/0HswXqAg56L++s=; h=X-UI-Sender-Class:Subject:From:In-Reply-To:Date:Cc:References:To; b=TzUTlQv4MHobXE7TxR7BJqk6OPz5lSmy5PqlznhRbSEvjKyAVlN159LfNQBOQqdgt lXKVvWPlKSVpcRE8scVDFUaKmS+r73rE31qleXXZZJDNSKaqfZIDWsbE0kuj2H1SO3 j5H5D0/W2dCG2KTbUzClgH8BTA22asGreUXQ9i/c=
X-UI-Sender-Class: 01bb95c1-4bf8-414a-932a-4f6e2808ef9c
Received: from [10.11.12.22] ([134.76.241.253]) by mail.gmx.com (mrgmx004 [212.227.17.190]) with ESMTPSA (Nemesis) id 1MdvmO-1jeimh1H5K-00b5rB; Thu, 27 Feb 2020 14:26:05 +0100
Content-Type: text/plain; charset="utf-8"
Mime-Version: 1.0 (Mac OS X Mail 12.4 \(3445.104.11\))
From: Sebastian Moeller <moeller0@gmx.de>
In-Reply-To: <AM4PR07MB349089E35D7888229455DE14B9EB0@AM4PR07MB3490.eurprd07.prod.outlook.com>
Date: Thu, 27 Feb 2020 14:26:04 +0100
Cc: Greg White <g.white@CableLabs.com>, "alex.burr@ealdwulf.org.uk" <alex.burr@ealdwulf.org.uk>, tsvwg IETF list <tsvwg@ietf.org>, Bob Briscoe <ietf@bobbriscoe.net>
Content-Transfer-Encoding: quoted-printable
Message-Id: <DF2C8FCC-3926-4B9B-A390-BED3829EC07F@gmx.de>
References: <09E7F874-41FE-483E-B6AA-4403DD5DA4AB@gmx.de> <AM4PR07MB34904548334F88D3E1D92452B9ED0@AM4PR07MB3490.eurprd07.prod.outlook.com> <78AF3DA5-5628-4D6C-B45D-EF001A070B9F@gmx.de> <1920156691.497732.1582720228792@mail.yahoo.com> <821788B3-49C8-46EA-BA16-E0686167B49C@cablelabs.com> <C28201FB-EC5C-4CA4-8B26-2B9CE3467535@gmx.de> <AM4PR07MB349089E35D7888229455DE14B9EB0@AM4PR07MB3490.eurprd07.prod.outlook.com>
To: "De Schepper, Koen (Nokia - BE/Antwerp)" <koen.de_schepper@nokia-bell-labs.com>
X-Mailer: Apple Mail (2.3445.104.11)
X-Provags-ID: V03:K1:DzuMFusD6vzfy7no6zBi3g2WdtKOKLyLi30zCuiDl5TO9IghOSN rG0RHwvCo5LgJ4rSChpzt0gaKi0oTFJL7mswCONg0P+tNbnlzecSRjXaEmW5hj4CSKVFOUG SoqQHTmmm4J8EFtG/GZ7am8IYVfOE/YqMOXaPqzusmaLQfUTC0kqJBbkxhz3bpi5T2p/WcJ 6gyEW14XadJBnDqZZq9DA==
X-UI-Out-Filterresults: notjunk:1;V03:K0:MIB9Rq7yE8I=:8Kcta3494hkTDay76dHRk6 nsmx5D39KgFDnDZVxnohPaUW1XlYRldo2clyHzCND3hQyF9bEcDbxy4pBdTVEACsTuzjeOrb9 kCOgzTTIsQo2jqVqtGNfQwTpJdNvETkPRpPXpuwrx6dOZhctZ6L+v807o3/6fegaEKB9Zk6+5 i82cF4N1Ln+VWrQ23QNFG5QXwAI4i+s0mgwjHJ7AFGz0IjBlT/UBCCC3RpQQFfNAXDq5ju6aK wdaZ3fEr3NTvjzS0aVIbp/0J2saRLAmF9L5ztFVC5Ek91FTSyPUIEe44sV3RTK5R0E0dMeKPP BAJ3O/It/RwBPBvEWma6ar1h3lvU80WDgh1xNIKBJyrNxUq7zbIOZEb1vl0Fn/FwZPnACJOTp l4mDI/owimJSZ/24YDBwVLgF0AnzY73++1RqeFzrnievZzW9aKa+GnzQbdHoNG2wVeaxkKGa1 wok4bzSdQ/3vSfTAaNCbZxxsUDOwxQd2t5BGUlpjTyfczEyy7+2j8EuBjU6keF23OY3YNzR02 M/kXqLwRuRs4TOLPrB0r45vy9cE5mrY0orXfsk1fkLP1Z3qvC1JWy+Zz804j0mya1ClD1BZpp Lr5aKRgYH/ntth/YtRZIm9VeJ8m9YZVMEnWq6rfS57lSH9v3zn2VeRoTDeixJTusAeyeSRSYI bM8dAu5wP4L6gCn1+YY2j/FqC5XDgsUTKmruYr1nloSWXLLMxfW/KxNSuIvAnVIzbXDM/NZiD Sym9F0O1ZiZ0mgWIgSuGQKRAFR48IzmQIOyskvnEGVHeurzWXLWAfVHB1ATCl/jjqT3yBIAQ5 whbEYqP6eRqSzeXrAPL8zm7/wwLq40cFBOuaY/6DBEwWYIExV4g3tsSLGGhoEpgDs9DXh9/b/ L2imMhZiGk+QKklr7YjPb4JmzbaEfKFVpQLdyyAuguhY6BRWQZmvnSZj7umqez4Fn+toHmOj6 AHUc27QqgNk9GdKa5/AD42OL23HyLna61XKxAXz3bNYLUBsq/yu1C2fb23fnlNFdgqpOMcW12 R1WhWlqER1WNdrFlDmYNpaoHzi5ZjcH7lvpTqAjxOVlXhmdZo4+HYRYv+25PT2/egE0rC+jKi EJ/rp331t0eFlpvipLT4uaotA8+ggHVXLQt5eg04voSjHVBhUqmw964JvVhjxj3zBNZZptz9M YKVTRQR7duBiQ9fyaL+AmYq20su7sgO+k9xsQjGNIdXpMcQOiCS4gF9De8TD4fiXvmM3sisM6 W3aS25bVOLkFcPZ1s5OHRm7JKgs3Sd+eJftfVIo5tAY0ZPnnkDULNt+ZMtiCXGVDhxk4LUNKP oso7i8f3Zz+tkIqvUr21kUpmjcNRXiIDfHwNEvywIl/aNe8lbVQ=
Archived-At: <https://mailarchive.ietf.org/arch/msg/tsvwg/193Quv3oIrPujd6LFBRYq3N0BD0>
Subject: Re: [tsvwg] Todays Meeting material for RTT-independence in TCP Prague
X-BeenThere: tsvwg@ietf.org
X-Mailman-Version: 2.1.29
Precedence: list
List-Id: Transport Area Working Group <tsvwg.ietf.org>
List-Unsubscribe: <https://www.ietf.org/mailman/options/tsvwg>, <mailto:tsvwg-request@ietf.org?subject=unsubscribe>
List-Archive: <https://mailarchive.ietf.org/arch/browse/tsvwg/>
List-Post: <mailto:tsvwg@ietf.org>
List-Help: <mailto:tsvwg-request@ietf.org?subject=help>
List-Subscribe: <https://www.ietf.org/mailman/listinfo/tsvwg>, <mailto:tsvwg-request@ietf.org?subject=subscribe>
X-List-Received-Date: Thu, 27 Feb 2020 13:27:05 -0000
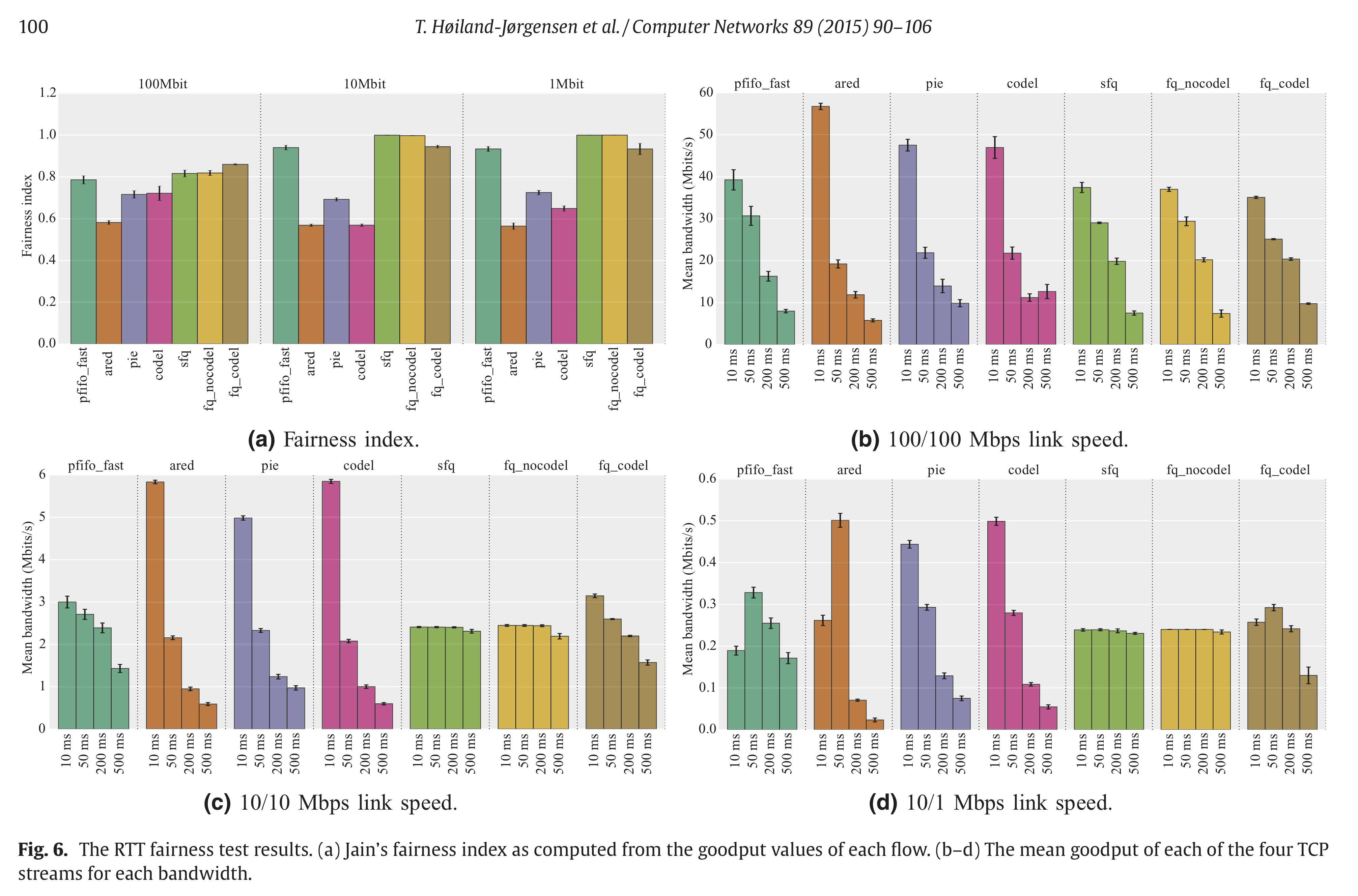
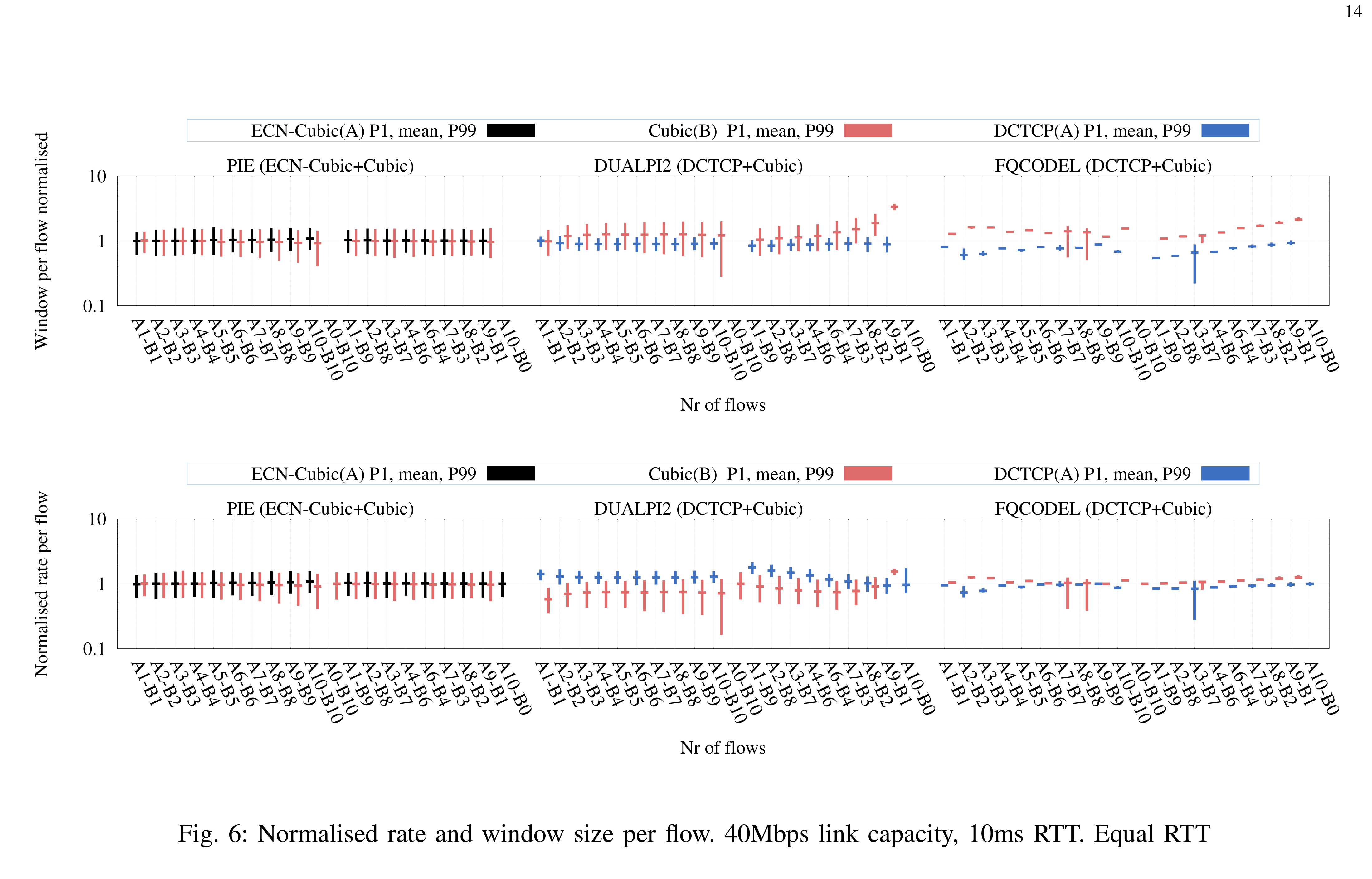
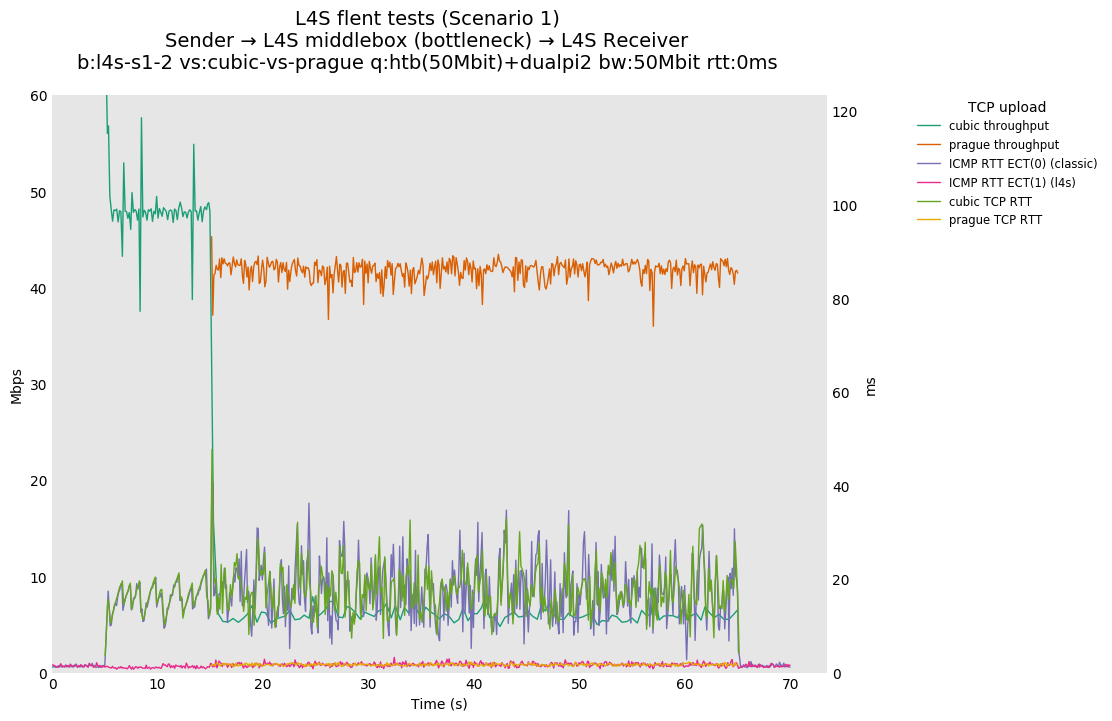
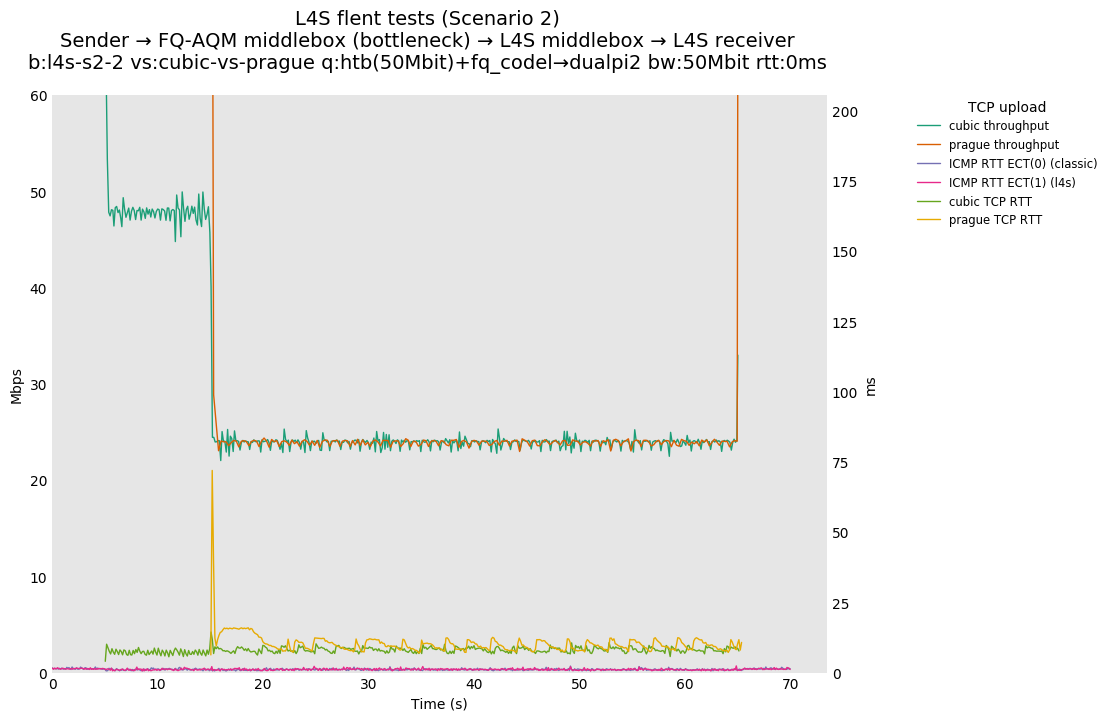
Hi Koen, more below in-line > On Feb 27, 2020, at 13:03, De Schepper, Koen (Nokia - BE/Antwerp) <koen.de_schepper@nokia-bell-labs.com> wrote: > > Hi Sebastian, > > I think we come closer to understanding the misunderstandings... > > This sentence clearly indicates where you have the wrong intuition about "coupling congestion control": > [SM] Well, per class fairness as an absolute lower requirement sort of falls out of the fact that dualQ operates two queues and supplies both with equivalent drops/markings to give the same amount of back-pressure to traffic of both classes, which should end in equal bandwidth sharing between the two traffic classes. > > If 2 classes of traffic get the same level of backpressure, the classes do NOT share the bandwidth equally. [SM] For quite a number of conditions they should share equitably, namely same number of flows at the same RTT. DualQ coupled AQM does not even achieve that as demonstrated in Figure 6 (page 14 of http://bobbriscoe.net/projects/latency/dctth_journal_draft20190726.pdf). I am happy to discus the minutiae and corner-cases but what I see is severe differences between what your drafts imply and what your solution delivers (and that is before we discuss what the draft should require to make it safe for the rest of the internet). At the very least you should make it very explicit in the drafts what kind of sharing behavior is to be expected if L4S gets deployed in a network so that one can easily predict the sharing behaviour one is going to see under realistic conditions. > The same backpressure per class leads to per FLOW sharing of bandwidth, as all flows see the same level of back-pressure the FLOWS converge to a state that send at a rate that matches this backpressure. Only if back-pressure/rate relation is fully RTT-independent, it will be the same rate. [SM] Fair enough, but as the data shows even for the case of an equal number of flows at equal RTT (equal RTT between the flows will make RTT-dependence irrelevant) the dualQ coupled AQM with back-pressure rate matched to the flows type (1/p or 1/sqrt(p)) fails to equitably share between CUBIC and DCTCP (I simply assume that this will also hold for TCP-Prague, as this is still a close relative to DCTCP). And I also realize that it is no coincidence that there is a systemic bias in dualQ to preferentially give the LL-queue more bandwidth. > As it is today, most congestion controls are window fair (so proportional to 1/RTT), which is influencing flow fairness already today. [SM] Agreed, but that is IMHO an orthogonal problem to dualQ's problems to equitably share in the situation where that should not matter much. > By reducing latency targets in queues (the RTT cushions) I agree we also need to reduce this RTT-dependency. [SM] As I said before, I am all for increasing RTT independence of transport protocols and also for trying smaller latency targets for the non-LL-queue's AQM. I am just not convinced that this is the proper place to fix the dualQ short-comings. > > If equal bandwidth per class would be the goal, we indeed would just have put some 50/50 RR scheduler in place without congestion coupling. The goal is to "act like a 'semi-permeable' membrane that partitions latency but not bandwidth", which means that we want to adapt the class rates to follow the number of flows and their "approximately equivalent" rates in each class. "approximately equivalent" means here indeed: the network does its best, the end-system has to do the rest... [SM] That does not make much sense to me at all. Let me elaborate, the solution to "we want to adapt the class rates to follow the number of flows and their "approximately equivalent" rates in each class" is a description of a problem which has a well known solution known as flow-fair or just fair queueing. You, and Bob, have repeatedly declared that that is an explicit non-goal. So how can you, at the same time want FQ-like behaviour and be adamantly opposed to FQ on theoretical/dogmatic grounds? Note, I am still not saying you need to go the FQ route, but if you argue like above be prepared that your solution will be compared with FQ alternatives, and currently unfavorably I would say. So to make this explicit, do you now argue that the goal is some weak sort of flow-fair queueing? If yes could you please explicitly state in numbers what kind of sharing imbalances (between flows and classes) you consider acceptable? > > Note that I am definitely NOT "allergic" to rate fairness. For me it is a default policy goal to try to achieve, but also not a "dogma" that needs to be "enforced" by all means. I see benefits in being able to deviate from this, like FQ_ also deviates and benefits from giving priority to single packet flows... I also don't like to "hard-code" the policy in the network [SM] I realize that you are very reluctant to restrict the future action and option space for L4S and I do understand the motivation for that, but I really think that the coexistence with existing traffic is too important to compromise safety now for the promise that that reduction in safety might potentially lead to interesting experiments in the future. > (unless it is clearly a policy agreed to be enforced, like per user FQ), rather let the rules be changeable and evolvable in the end-systems (for example FQ is using hard-coded the 5 tuple and only supports UDP/TCP flows, and future new protocols are not supported). [SM] cake, one of Linux's more recent qdiscs support quite a number of user-selectable isolation-type/flow definitions, like (flowblind), srchost, dsthost, hosts, flows. Note "flowblind" does not do FQ at all, "flows" requires the TCP/UDP transport headers, the others operate on the IP header only. Cake even offers a few isolation modes where a primary per host address is combined with a secondary per-flow isolation. So in short FQ-AQMs can and do evolve to match the requirements of the day. I see for example no reason, why a sufficiently popular new protocol might not also cause cake to grow a new specific isolation mode or the flows mode to learn to evaluate that flow's diagnostic L4 information. Also with IP itself not going away anytime soon, for quite a number of network locations pure IP header based FQ should work well, even for new transport protocols, no? That said the probability of a new protocol being a viable option was judged sufficiently small in your RFC drafts to dismerit the obvious idea of using new protocol numbers as the identifier of 1/sqrt(p)-type congestion response, so this seems a bit artificial to bring up now. > Also FQ is isolating flows, so they cannot collaborate. [SM] By what definition of collaboration can two independent data transfers collaborate? > One pertinent example are back-ground congestion controls that only want to use available bandwidth not used by others. With FQ they get exactly the same rate again as an urgent download or your high definition (hopefully adaptive) video stream. Same for deadline aware congestion controlled flows, they are all put in isolation. [SM] Partly, FQ by itself does not really solve any of these issues. But for example LEDBAT, can work well with fq_codel assuming one replaces LEDBAT's atrocious default 100ms acceptable latency-under-load-increase value with something tailored to the AQM's target delay (that is by default use say 2.5ms for LEDBAT over Codel). There are also other methods by which a back-ground protocol can make itself less problematic (think harder faster MD and slower gentler AI, stronger, longer lasting responses to drops/CE marks). Or one could start using the LE-PHB so that network node know which packets should be dropped preferentially. But more to the point, ubiquitous FQ AQMs probably would have squelched the need for scavenger protocols like LEDBAT as their main justification rarely is bandwidth use, but rather the undesired side-effects on a links latency if it is saturated with bulk traffic. And yes, often the node at the bottleneck of a network path does not have sufficient information None of this is particularly relevant for the dualQ AQM question though. > > So ultimately we also want to support perfect per flow rate sharing (even further than FQ, because it also support new protocols, tunnels, ...), only realistically, existing congestion controls have their limitations, and we propose to improve them where possible and fitting the migration/deployment story (Prague requirements). Will it be perfect? No. Will it be good enough? > Definitely, a lot better than it is today. Is FQ_ perfect? No, but also better than it is today. Does L4S or FQ cover all corner cases? No. We can think of corner cases for both were with is worse than without. > > Is 1:8 a proof of "catastrophically brokenness"? If this is your opinion, then everything is "catastrophically broken". [SM] Please note that this is catastrophic as that is the apples to apples comparison, equal number of flows, equal RTT, that is if you will the easy case. Getting that wrong is typically not a good sign for the hard cases. > Think about a Codel AQM with 5ms target controlling a flow with RTT 0ms and another of 40ms: a 1:8 case, so Codel is catastrophically broken? Think about an FQ-Codel AQM controlling two flows of which one is a tunnel encapsulating 8 downloads: a 1:8 case, so FQ- is catastrophically broken? [SM] IMHO you are mixing up orthogonal things here, dualQ's inability to equitably share in the easiest of conditions and the effect of differential RTT on per flow fairness. I just note that according to https://abload.de/img/thegoodthebadthewifimorjjh.png (https://www.researchgate.net/publication/281270130_The_Good_the_Bad_and_the_WiFi_Modern_AQMs_in_a_residential_setting) the fairness indices for flows of different RTTs of FQ-based AQMs like sfq, pure FQ with taildrop, fq_codel, seem consistently closer to the the fairness of both 1 and to that of the no-AQM reference, than single-queue AQMs like ared, pie and codel. So following your arguments you probably could have started your experiments from a FQ-based AQM as it seems to be in almost all aspects closer to your goals than the solution you converged upon (short of the n-FQ condition). Regards Sebastian > > I hope this clarifies, and puts expectations in a more realistic perspective. Let me know if you (or others) still see issues/cases that are really important to solve (show stoppers) related to this mail thread (RTT-independence). > > Thanks, > Koen. > > > > > -----Original Message----- > From: Sebastian Moeller <moeller0@gmx.de> > Sent: Thursday, February 27, 2020 9:54 AM > To: Greg White <g.white@CableLabs.com> > Cc: alex.burr@ealdwulf.org.uk; De Schepper, Koen (Nokia - BE/Antwerp) <koen.de_schepper@nokia-bell-labs.com>; tsvwg IETF list <tsvwg@ietf.org>; Bob Briscoe <ietf@bobbriscoe.net> > Subject: Re: [tsvwg] Todays Meeting material for RTT-independence in TCP Prague > > Hi Greg, > > now I am puzzled, more below in-line. > > @Bob, Koen, please have a look at the SIDENOTE section about a question regarding Figure 6 of http://bobbriscoe.net/projects/latency/dctth_journal_draft20190726.pdf > >> On Feb 27, 2020, at 01:45, Greg White <g.white@CableLabs.com> wrote: >> >> Alex, >> >> I think this summarizes it well. > > [SM] I gave a detailed response to Alex's mail with references to data, L4S draft text an other in-force RFC text relevant t the matter at hand. I would be delighted if you could respond to that post as well and show where my analysis is wrong. > > > >> >> Per-class fairness is definitely not an agreed requirement, and it won't be. > > [SM] Well, per class fairness as an absolute lower requirement sort of falls out of the fact that dualQ operates two queues and supplies both with equivalent drops/markings to give the same amount of back-pressure to traffic of both classes, which should end in equal bandwidth sharing between the two traffic classes. > > >> With per-class fairness, L4S flows would each get 100x the capacity of classic flows in cases where there are 100x as many classic flows as L4S flows. > > [SM] I would expect something like that yes, and I consider this to be sub-optimal, but I realize the L4S team is highly allergic to flow-fair queueing so this is one of the desired outcomes, otherwise you would just have put a requirement for a flow-fair AQM into the L4S spec that also treats each flow to the appropriate ECN signallng. BUt the L4S team did not doe this for a reason, partly because BoB considers per-flow fairness as a damiging concept. I disagree on the relative merits of FQ, BUT I accept that in the L4S architecture you do not want to guarantee per-flow fairness and hence am only arguing for a weaker isolation guarantee. An isolation type that, as I might add, is strongly implied in the text of both the l4s-arch and the dualQ rfc drafts. > > >> DualQ provides a much better outcome than that across a range of conditions. > > [SM] Please give your definition of goodness here, so I can try to understand what you are actually arguing for. > > >> The conditions where it does not perform as well as desired are being >> worked on > > [SM] I do not believe this statement to be correct. The L4S team is addressing a few failure conditions that have been pointed out here, but there is still ample space for improvements. For example above you seem to argue for per-class-fairness being insufficient, and indicate in your example that per-flow fairness might be your goal. But here I point you to Figure 6 (page 14 of http://bobbriscoe.net/projects/latency/dctth_journal_draft20190726.pdf) https://abload.de/img/dctth_journal_draft206xjsi.png The lower panel shows the normalized rate per flow for different numbers of flows per class, note how the blue DCTCP flows always outcompete the CUBIC flows? The first ten columns (in the middle section titled DUALPI2 (DCTCP+Cubic)) show that for equal numbers of flows the LL-queue maintains a noticeable rate advantage, and that per-flow bias mostly is maintained even when the number of flows per class is varied. > I have seen zero indication that this systemic per-flow imbalance is being worked on, please direct me to any on-going work to remedy this. > > > SIDENOTE: Figure 6 lower panel middle section last sub-columns A10-B0 contains only a blue data point (indicating DCTCP), while Figure 6 upper panel middle section last sub-columns A10-B0 only contains a red data point (indicating CUBIC). Judging from the descriptions spread over the text, the letter A should always refer to red and CUBIC, so I humbly request that the authors have a look again at Figure 6 and either explicitly explain why this is to be expected or fix the bug. > > >> (and promising results have been shown) by the Prague team. > > [SM] The only thing I have seen is the gross hack to graft the 10ms ref_delay for dualQ's non-LL queue into TCP Prague. > > >> >> Precise per-flow fairness has never been a requirement or claim for single-queue or dual-queue systems. > > [SM] Yes, I have accepted that premise* and hence I only argue that at least per-class fairness should be maintained, I am happy if you err on the side of existing traffic, but what is unacceptable to me is to release an AQM into the wild which under realistic conditions starves one traffic class completely, as has been amply demonstrated for the dual queue coupled AQM since the beginning. > > If the WG/IETF decides that the current L4S approach is safe enough to merit experimental RFC status and deployment, fair enough, but I want to make sure that everybody involved is acutely aware of the unsafe side-effects /design decisions of the dual queue coupled AQM before standardization. > > I add that the SCE-drafts demonstrate that there is a viable way to deploy 1/p-type ECN signaling in a way that by design safely coexists with the existing internet. > > > Best > Sebastian > > > *) I am starting to question whether you actually still read what I write, as I have made that point about L4S not having to demonstrate flow fairness repeatedly now, so why does this still come up? Now, I also realize that flow-fair queueing is a pretty decent heuristic for any network node lacking reliable other information about packets that could be used to make a "better" decision how to share bandwidth between active flows. > I know, Bob keeps arguing the there are scenarios in which FQ is not the optimal solution, while I keep stressing that there an equal number of scenarios where FQ is not the pessimal solution; simply permute the optimal un-equal bandwidth distribution between flows, et viola, a non-optimal distribution probably worse than FQ. And since network node typically lack sufficient information to find the optimal distribution, I consider FQ to be an approach that is both good and predictable enough to merit consideration as standard solution. But L4S is not the standard draft for that, and as I said, I accept that and try to measure dualQ's performance/behavior against the L4S drafts as well as other applicable RFCs. > > >> >> -Greg >> >> >> >> >> On 2/26/20, 5:30 AM, "tsvwg on behalf of alex.burr@ealdwulf.org.uk" <tsvwg-bounces@ietf.org on behalf of alex.burr@ealdwulf.org.uk> wrote: >> >> Sebastian, >> >> >> On Tuesday, February 25, 2020, 6:39:08 PM GMT, Sebastian Moeller <moeller0@gmx.de> wrote: >> >>> the short answer to the question " why you keep on saying/repeating >>> that DualQ is broken" is. Because the class isolation component of this AQM is considerably worse than the state of the art. >> >> [AB] I believe there is some confusion here. AFAICT the L4S AQM does not have a class isolation component in the sense you are talking about. >> My understanding is: >> - Today, in single queue bottlenecks, flows cooperate to split the bandwidth. >> - FQ systems render this unnecessary by deciding in the network the bandwidth allocated to all flows. >> - L4S has a goal of extending the existing 'cooperate to split the bottleneck bandwidth ' system to flows which use different congestion signalling mechanisms. >> >> In order to cooperate, the flows cannot be isolated. >> >> There is some verbiage about 'latency isolation' in the L4S drafts, which may be the source of this confusion. >> >> It seems to me that arguing about isolation as if it were an agreed requirement has been the source of much unnecessary frustration on both sides. >> It is legitimate to a) advocate for flow or class isolation, or b) to point out circumstances in which L4S has not achieved the cooperation which is is claiming. But I do not see that the WG has, at the time of writing, already decided that class isolation is a requirement for allowing new congestion signalling mechanisms onto the internet. For example, I do not see this specified in rfc4774. Perhaps I have missed something, but for this to be a requirement, I think you need to convince the WG. >> >> Alex >> >> >> >> >> >> Please compare https://l4s.cablelabs.com/l4s-testing/key_plots/batch-l4s-s1-2-cubic-vs-prague-50Mbit-0ms_var.png (dualQ @ 0ms added RTT, throughput ratio ~1:8) with https://l4s.cablelabs.com/l4s-testing/key_plots/batch-l4s-s2-2-cubic-vs-prague-50Mbit-0ms_var.png (fq_codel @ 0ms added RTT, throughput ratio ~1:1). Note how dialQ performs catastrophically worse than fq_codel under otherwise similar conditions. With just two flows (one TCP Prague and one cubic), fq_codel here acts as a per-class-fair AQM, perfectly sharing the bottleneck bandwidth between the two flows/classes. That is what I consider the state of the art. >> I hope that if the L4S team deploys an AQM on the internet that this will not regress in comparison what is achievable and already out there. >> Before somebody is going to misunderstand the point I am making here. I am NOT proposing you use fq_codel or flow queueing in general, but I do propose that you use an isolation mechanisms between your two traffic classes that is at least as robust and reliable as fq_codel's. As far as I can tell this level of isolation is a solved problem and not getting close to that is something I consider to be a deficit or brokenness. >> >> >> >> >> >>> On Feb 25, 2020, at 17:46, De Schepper, Koen (Nokia - BE/Antwerp) <koen.de_schepper@nokia-bell-labs.com> wrote: >>> >>> Hi Sebastian, >>> >>> What I showed in the demo is what you called below B). >> >> [SM] Thanks for clearing this up. >> >>> It was a convenient play-example to easily show that we can fully control the RTT-function f(). It compensates the 15 ms extra latency that classic flows gets by needing a bigger queue. So f()=RTT+15ms, making both Prague and classic flows getting exactly the same rate if they have the same base RTT. It is not our recommended f(), it was just simple to show. >> >> [SM] Okay, as I said it is a nice hack to support the hypothesis that dualQ's isolation method is insufficiently strict. >> >>> >>> If you want A) you need the following f()=max(15ms, RTT), meaning that any flow behaves as a 15ms flow (if it's real RTT is not bigger than 15ms). >> >> >> [SM] It is not so much that I "want" A) but that you promised A), by calling this RTT-independence... >> >>> We haven't tested RTT independence for flows with a larger real RTT than the target RTT. >>> We'll leave that up to others to further test/improve the throughput for higher RTTs (which everyone seems to accept). >>> >>> >>> The following plot shows for A) where f()=max(15ms, RTT), the throughput for different 2-flow RTT-mixes (similar as in the paper you referred to): >>> https://l4steam.github.io/40Mbps%20RTT-mix%20Prague-RTT-indep.png >> >> [SM] Thanks, appreciated. >> >>> As you can see on the left half, flows below 15ms become RTT independent (get the same rate), and on the right half, lower than 15ms RTT flows are limited pushing away higher RTT flows (100ms here) up to one comparable to a 15ms flow. >> >> [SM] Yes I see. Calling that "RTT-independence" is a bit of a stretch though, no? >> >>> >>> Our implementation has currently both implemented as an option plus one extra proposal function that Bob provided (gradual changing - with a limited RTT independent for the lower RTTs). More on that later. >> >> [SM] So don't get me wrong, according to your slides the requirement "Reduce RTT dependence" has the status "evaluat'n in progress" how about you share the data/slides that you already have (like the figure above)? That would allow a considerably more data-driven discussion. >> >> >>> >>> To be clear we don't propose B), rather something A)-like with a bit lower target RTT (5ms?) that still gives benefits for lower RTTs, but also limited like Bob proposed. >> >> [SM] My problem with this approach is not necessarily the fact that plugging the 15ms number from the non-LL-queues AQM at some other place to undo its damage. But the fact that this other place is completely outside the node that will actually run the L4S-aware AQM. It is fine IMHO to have endpoint protocols to work with heuristics and approximations to deal with the existing internet, but I really wonder whether the need to modify a not-deployed-yet and un-finished protocol to make up for avoidable design decisions for a not-deployed-yet and un-finished AQM might not indicate that something is off. >> >>> >>> Other possible solutions are: >>> - have the Classic AQM target at 1ms too >> >> [SM] Which will work great for RTTs in the 10-50ms range but will cause utilization issues at higher yet still realistically common RTTs, the reason why I keep asking for a test with 5ms is that this with Codel and Pie works reasonably well ven for true RTTs in the >= 200ms range. >> >>> - have a bigger coupling factor >> >> [SM] Will that actually solve the problem though? My intuition tells me that this will just shift the conditions around under which LL pummels non-LL traffic. >> >>> - make classic TCP RTT independent in the higher RTT range >> >> [SM] Not a viable option, we need to work with the already deployed TCPs reasonably equitable. This was in jest, surely? >> >>> - FQ >> >> [SM] Don't get carried away, in your case all you need is fairly distribute between two classes queues, you could still call this "fair" queueing if referring to fairness between classes but CQ, class queuing might also be a less contentious name for it,. IMHO that a limited two class strict fairness scheduler is the proper solution, but I do not claim that there are not better fitting solutions around that achieve a similar robust and reliable isolation between the two traffic classes L4S considers. >> >>> - provide RTT info in the packet header >> >> [SM] Theoretically a nice idea, but will not help with the existing internet much. >> >>> - ... >>> but I don't think people will in general favor these... but if possible they are still usable. >> >> [SM] Well, the two class fair queueing option seems like a winner to me. >> >>> >>> I don't understand why you keep on saying/repeating that DualQ is broken. >> >> [SM] If a new solution to an old problem falls well behind the current state of the art, I consider the design of the new solution in that specific dimension to be insufficient or defective. >> >> >>> DualQ wants to reduce the latency for L4S, but it cannot do the same for Classic, because of limitations of Classic congestion control itself. >> >> [SM] Fair enough, but the way you implemented that feature is by also giving L4S a massive "bandwidth" advantage and that is not how you frame and sell the whole L4S idea in the first place. >> >>> We don't make Classic traffic RTT dependent, it is already RTT dependent, and has been since the beginning of congestion control. >> >> [SM] And it will stay RTT dependent just as TCP Prague will retain at least a residual RTT dependence, since shorter control loops are nimbler than longer ones, and the only general available option (make all congestion controller behave as if behind the maximum possible RTT) is clearly not suited for anything but Gedankenexperimente. >> >> >>> So my conclusion is that the problem is with TCP congestion control that is RTT dependent and Classic that is not happy with a short queue. How do you suggest to solve this other than making TCP less RTT dependent??? >> >> [SM] Use something like DRR++ to schedule packets from the two queues you still use to separate 1/p-type traffic from 1/sqrt(p)-type traffic, Use what ever classifier you want* to steer packets in one of the queues, and instantiate your two differential marking regimes depending on the traffic's type, that should solve most of the issues right there. The scheduler will make sure both queues share the egress traffic equitable and the rest just stays as is in you L4S design, except you might be able to abandon the cute but only approximate coupling idea** and deduce each queue's marking rate directly from its occupancy level/sojourn time. >> Now, this will solve the particular issue I a concerned about, backward compatibility and equitable sharing with existing traffic***. It might well fall short to meet some of your design goals and requirements, I would appreciate if you could describe how and why the proposed scheme would not work for L4S? >> >> Regards >> Sebastian >> >> *) Actually I would strongly recommend to use a DSCP for the required marking, at least in addition to what ever else you end up picking. >> **) If coupling would solve the issue we would not have this discussion... >> ***) I note that until L4S actually drives 50% of internet traffic equitable sharing is already giving a strong bandwidth bias towards L4S at bottleneck links. That is something I am not happy with, but not something I have a better solution for that you will find acceptable. >> >> >> >> >> >>> >>> Regards, >>> Koen. >>> >>> -----Original Message----- >>> From: tsvwg <tsvwg-bounces@ietf.org> On Behalf Of Sebastian Moeller >>> Sent: Friday, February 21, 2020 9:00 AM >>> To: tsvwg IETF list <tsvwg@ietf.org> >>> Subject: [tsvwg] Todays Meeting material for RTT-independence in TCP >>> Prague >>> >>> Dear All, >>> >>> >>> after today's virtual meeting I am still pondering Koen's RTT-independence day presentation. The more I am thinking about this the more confused I get about what was actually achieved. >>> >>> Was it: >>> A) true RTT independence between TCP Prague flows so flows of wildly differing RTTs will share an L4S AQM's LL queue fairly? >>> >>> B) class RTT independence, that is adding the so far under-explained 15 ms target for L4S's non-LL queue to the internal RTT response generation in TCP Prague (which, let me be frank would be a gross hack and solving the right problem (dualQ's failure to meet its goals robustly and reliably) at the wrong position)? >>> >>> C) all of the above? >>> >>> I had a look at the slides, and all I see is B) and no data for A), and IIRC the demo also focused on B), dod I miss something. If you have data for A) please share with us, because B) alone is not well-described with the RTT-independence moniker. >>> >>> Question: is it just me, or do others also get uneasy when a yet un-deployed transport protocol modification (TCP Prague) grows a magic +14.5ms constant somewhere in its innards to work-around the existence of another under-explained 15ms constant somewhere in the innards of another yet un-deployed AQM, INSTEAD of simply fixing said un-deployed AQM to not require such and ugly hack in the first place? Are all L4S compliant transports expected to grow the same ~15ms constant? >>> What if in the future the dualQ AQM is superceded by something >>> else, that for good justification* wants to implement a target of >>> 5ms, do you envision all modified transport protocols to be >>> changed?** >>> >>> >>> The fact of the matter is, the dual queue coupled AQM as currently >>> implemented is broken, but I see >>> >>> >>> The rationale why the magic f() would have been added to TCP Prague without the need to paper over dualQ's major failure was a bit thin in Koen's presentation, so please supply me with more reasons why this is a good idea and not simply the cheapest way to paper over dualQ brokeness without actual real engineering to fix the root cause? >>> >>> Also, please show how these modifications make bandwidth sharing inside the LL-queue more equitable and significantly less RTT-dependent, ideally by using a similar mix of flows like in The Good, the Bad and the WiFi: Modern AQMs in a residential setting: T.Høiland-Jørgensen, P. Hurtig, A. Brunstrom: https://www.sciencedirect.com/science/article/pii/S1389128615002479, so that your results can be compared to figure 6. Until that point I will assume that increased RTT-independence is still aspirational. >>> >>> Best Regards >>> Sebastian >>> >>> >>> >>> *) I note again, that the CODEL RFC has a section that gives some rational why 5ms is a reasonable target value for flows in the 20-200ms RTT range, and that the PIE proponents have not presented any clear study demonstrating that the chosen 15ms is optimal in any dimension, which would be interesting as DCSIS-PIE actually seems to default to 10ms... >>> >>> >>> **) This is another sticking point, I have asked the L4S team repeatedly to use their test-bed (which should make testing different configurations a breeze), to measure between-class fairness and link-utilization between the LL- and the non-LL queues for short medium and long RTTs with the non-LL-queues target set to 5ms. >>> And so far all I hear is something along the lines of, if that interests me, I could do my own tests. My interpretation is that either the test bed is far less flexible and easy to use, or there is the fear that the 5ms data would reveal something unpleasant? >>> >>> >>> >> >> >> >
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- [tsvwg] Todays Meeting material for RTT-independe… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… De Schepper, Koen (Nokia - BE/Antwerp)
- Re: [tsvwg] Todays Meeting material for RTT-indep… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… alex.burr@ealdwulf.org.uk
- Re: [tsvwg] Todays Meeting material for RTT-indep… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… Greg White
- Re: [tsvwg] Todays Meeting material for RTT-indep… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… De Schepper, Koen (Nokia - BE/Antwerp)
- Re: [tsvwg] Todays Meeting material for RTT-indep… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… De Schepper, Koen (Nokia - BE/Antwerp)
- Re: [tsvwg] Todays Meeting material for RTT-indep… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… Rodney W. Grimes