
Re: [tsvwg] Todays Meeting material for RTT-independence in TCP Prague
Sebastian Moeller <moeller0@gmx.de> Wed, 26 February 2020 15:40 UTC
Return-Path: <moeller0@gmx.de>
X-Original-To: tsvwg@ietfa.amsl.com
Delivered-To: tsvwg@ietfa.amsl.com
Received: from localhost (localhost [127.0.0.1]) by ietfa.amsl.com (Postfix) with ESMTP id C9B443A09F7 for <tsvwg@ietfa.amsl.com>; Wed, 26 Feb 2020 07:40:15 -0800 (PST)
X-Virus-Scanned: amavisd-new at amsl.com
X-Spam-Flag: NO
X-Spam-Score: -1.648
X-Spam-Level:
X-Spam-Status: No, score=-1.648 tagged_above=-999 required=5 tests=[BAYES_00=-1.9, DKIM_SIGNED=0.1, DKIM_VALID=-0.1, FREEMAIL_ENVFROM_END_DIGIT=0.25, FREEMAIL_FROM=0.001, SPF_HELO_NONE=0.001, SPF_PASS=-0.001, URIBL_BLOCKED=0.001] autolearn=no autolearn_force=no
Authentication-Results: ietfa.amsl.com (amavisd-new); dkim=pass (1024-bit key) header.d=gmx.net
Received: from mail.ietf.org ([4.31.198.44]) by localhost (ietfa.amsl.com [127.0.0.1]) (amavisd-new, port 10024) with ESMTP id SYFHQOS364Ox for <tsvwg@ietfa.amsl.com>; Wed, 26 Feb 2020 07:40:12 -0800 (PST)
Received: from mout.gmx.net (mout.gmx.net [212.227.17.20]) (using TLSv1.2 with cipher ECDHE-RSA-AES256-GCM-SHA384 (256/256 bits)) (No client certificate requested) by ietfa.amsl.com (Postfix) with ESMTPS id AA9183A09BC for <tsvwg@ietf.org>; Wed, 26 Feb 2020 07:40:11 -0800 (PST)
DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/simple; d=gmx.net; s=badeba3b8450; t=1582731607; bh=o+SLu/kgT1r631Df+jzeGqC+3428WEuKyC4qA+96FdE=; h=X-UI-Sender-Class:Subject:From:In-Reply-To:Date:Cc:References:To; b=A89fUJYl1GZllboIGgmifGvdo134VOItNDrBcrFelnIK7TbS3Zknrgd5GIDK7MRmL dXoVbzofXouZWiIYUExw6kdSuPgxmUXp0B0qKTy2NNJjKZFlesS1t+yOMroH0XQvae i/A92jpiG7eiNjmIlHNFYqzE32CPWjVGgefenW84=
X-UI-Sender-Class: 01bb95c1-4bf8-414a-932a-4f6e2808ef9c
Received: from [10.11.12.22] ([134.76.241.253]) by mail.gmx.com (mrgmx104 [212.227.17.168]) with ESMTPSA (Nemesis) id 1MatVb-1jhyVI0lv1-00cRYK; Wed, 26 Feb 2020 16:40:07 +0100
Content-Type: text/plain; charset="utf-8"
Mime-Version: 1.0 (Mac OS X Mail 12.4 \(3445.104.11\))
From: Sebastian Moeller <moeller0@gmx.de>
In-Reply-To: <1920156691.497732.1582720228792@mail.yahoo.com>
Date: Wed, 26 Feb 2020 16:40:06 +0100
Cc: "De Schepper, Koen (Nokia - BE/Antwerp)" <koen.de_schepper@nokia-bell-labs.com>, tsvwg IETF list <tsvwg@ietf.org>
Content-Transfer-Encoding: quoted-printable
Message-Id: <0452C735-8585-46A2-B1FB-4BB0BA6A5ECF@gmx.de>
References: <09E7F874-41FE-483E-B6AA-4403DD5DA4AB@gmx.de> <AM4PR07MB34904548334F88D3E1D92452B9ED0@AM4PR07MB3490.eurprd07.prod.outlook.com> <78AF3DA5-5628-4D6C-B45D-EF001A070B9F@gmx.de> <1920156691.497732.1582720228792@mail.yahoo.com>
To: "alex.burr@ealdwulf.org.uk" <alex.burr@ealdwulf.org.uk>
X-Mailer: Apple Mail (2.3445.104.11)
X-Provags-ID: V03:K1:GKTIAbtwsny0uHS2t1OwdEUDkpCNX1hR8K3L+Gvcnl5NXY1HbrM SCLLF/dqAK25zsH6PBgvyf4XzcSFNnW/Xqh0Zh4s8nXZEn2FglNLueQ0E0hHFutWaPnznFZ iRYSSBMcHsn7xRE6pHwdW5/0RVtYdckhAc4z+6RAXmmCTJO7D5m/0zkUlpfsOHdnK6vRDfr 6UgU0Ww6aKhagyT5jpw3w==
X-UI-Out-Filterresults: notjunk:1;V03:K0:QUmKUvuiKRY=:kOVMT4T8b2hWkV6PHDGADX r4tPgFcpsCO5QtvZEGZ5v1PvPNeAN1Qwx8On3GO8+DBo+Tj2xzVq39P9JKPMbvhqcK7Y1ZoFV PPSYKPuo4M1bzEzBd9jwi8+kuuU3ToMfJBTWB5wvyFgta96cPIzIY5vGpvFziGel+On5uJnSP cppVJ4gv0dVBHFWZM2F6syp8qPTXSapj0omDBVV8PP4huBhQdoKDIa5Hkmump6hlffuvc/Nfg I85CVqliIu4vk3bpInmIIFs+LXDYOEqYuzwd+DQ4gRKTHVK6eAkmCT+enbH0H1stjpgxZVxsy ImImU09DOQuzb6BHSBrW1q5dXmuQ0q88dz2QEK75FSoRdWae9I/xklGzn/ti0NvvHRy+6kiPK 4bwuEPyiTr2bpemRdyYfSEALBZqCtQ63Jg+MSvtmUbqKX5X2XrVlRHjG+/CrL3THj9qDLznSq v/9O0bAlMc4Ei5WX7qYDzJ2cfDLsn51AZbVkTHR9QyeTaMF0AFF2opfbh2zFL2/1SJZg3Lssb QKDU94Fh1bofDyzWiOLXY2by/kyeUCSHJ4uJWfjZAz2jkrthNWWrv9tljzPwiOsbIt2TAeojr Ih5O7mWRuhteD3VlPiHLlnDxrdVZSaGajn9RHLc19UOUV047D9uyzrCALjGbccVODf2CnUIiy eTGeg+o9Tr86B2DlOMSKvJNVt4Y11U8VYkeVv3UuKo9jPrYZZTkJGiOZbvNT3jYNGI/aYUXFZ AqY9jre66aF4ucb8PbDPihkU1VT46LHFeRf4zt6fO5Ftegb4q/c8+HuuGwf7Zj0jNi0AWxi8T J/ql2xdn9IzKXbA6LyEH4w0OOEsDsPw4/Qn3EnAfr3PlgnOOsVskIGtnZAJOLLMr1ggU3KinH ygK1MJ/GUhVAQv2VAF9xbOEPCbc6OdTvbnjo7WUNUG3tlAv6MYrIgOGAZAsrWap2AW5ATRvXL XiYJetTJmndZ3AwpIaLVh0fhALwFrFkaX5AqwbBo9IXekvnHHGbfShBFlhZAMNKgkop6h+wsI Os8CODY+plBHNooqkDoXpYXyFM+wKLVnFCtj5y8Zmfd4cP8GH4gcWmGmLzHb2Cx+X4yKEMDBG Sgctm0w2ufYWIKnTNxriCYyzSOzwnvVM0CxHwku2IIuYS9VEDaj+cVoJVPMNHNxFvUhJkDm85 ddy6ZOwaAqgrLMxtqHVHyfnYCb4/xtelzcbFaffaJv6k/cqDlkm4arn3AFJzDxkKjtPosYDk7 2VGBbmQajyFMOWBPS
Archived-At: <https://mailarchive.ietf.org/arch/msg/tsvwg/BLGITT5XN8o-AJli4xz2P_VFxqs>
Subject: Re: [tsvwg] Todays Meeting material for RTT-independence in TCP Prague
X-BeenThere: tsvwg@ietf.org
X-Mailman-Version: 2.1.29
Precedence: list
List-Id: Transport Area Working Group <tsvwg.ietf.org>
List-Unsubscribe: <https://www.ietf.org/mailman/options/tsvwg>, <mailto:tsvwg-request@ietf.org?subject=unsubscribe>
List-Archive: <https://mailarchive.ietf.org/arch/browse/tsvwg/>
List-Post: <mailto:tsvwg@ietf.org>
List-Help: <mailto:tsvwg-request@ietf.org?subject=help>
List-Subscribe: <https://www.ietf.org/mailman/listinfo/tsvwg>, <mailto:tsvwg-request@ietf.org?subject=subscribe>
X-List-Received-Date: Wed, 26 Feb 2020 15:40:22 -0000
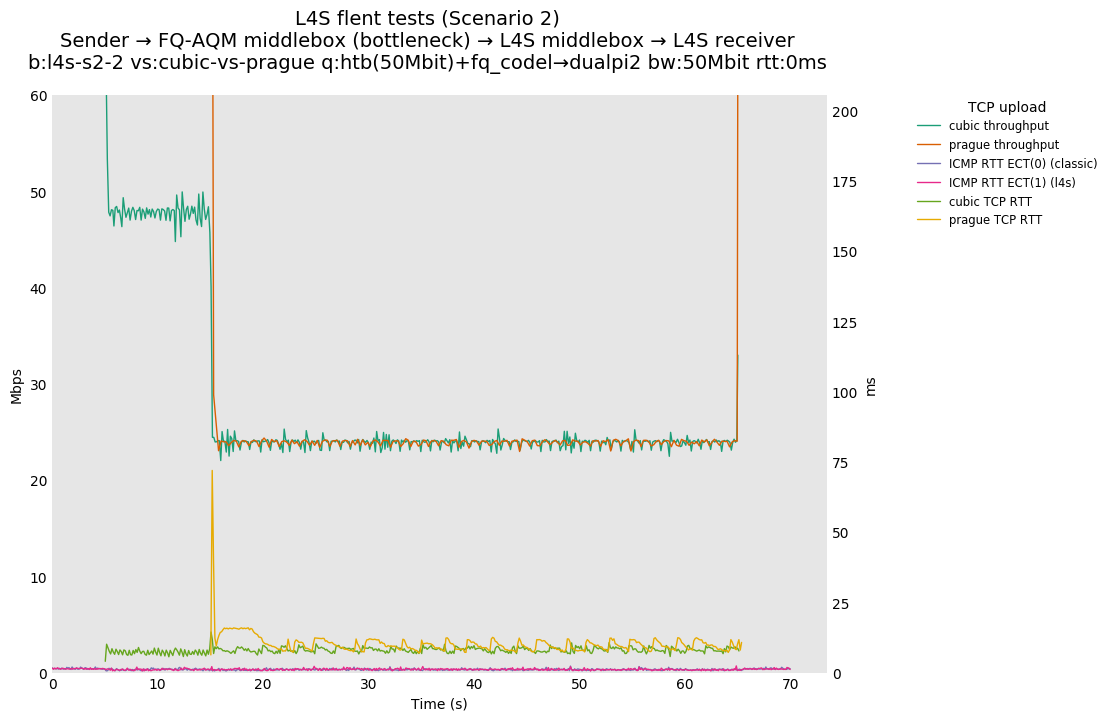
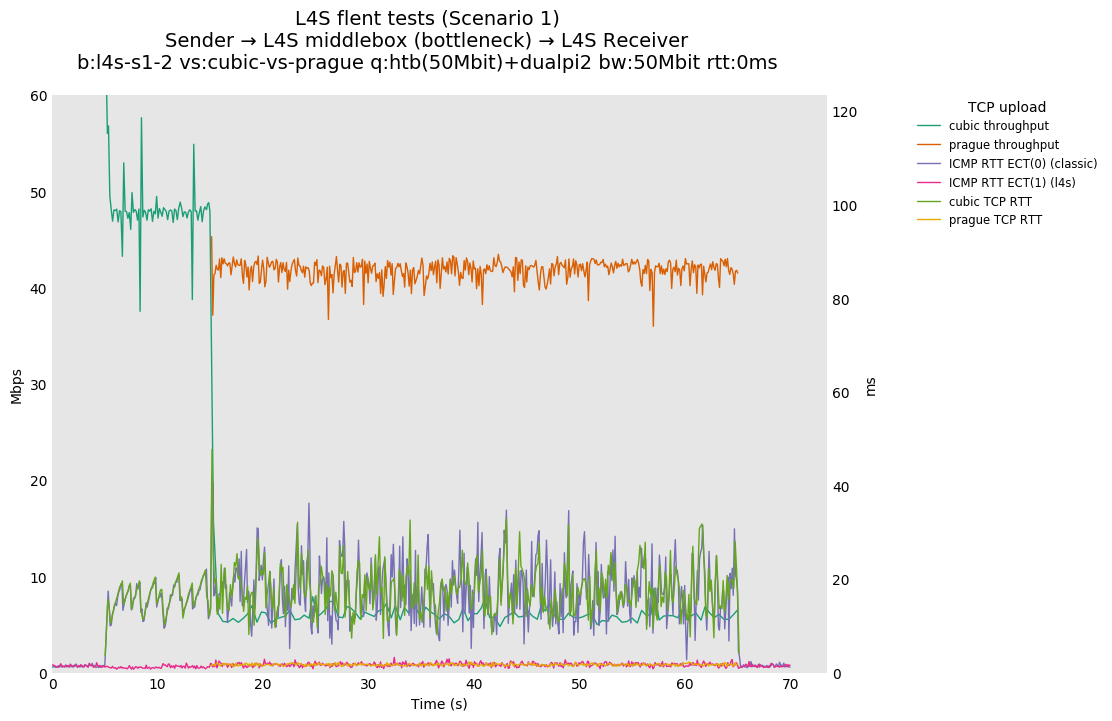
Dear Alex, thanks for you input. Do I understand you position correctly, that you consider equitable sharing between the two traffic classes L4S sorts "the world" into as optional? From https://tools.ietf.org/html/draft-ietf-tsvwg-l4s-arch-05: "The L4S architecture provides an approach that allows for the deployment of next generation congestion controllers while preserving reasonably fair coexistence with Reno and Cubic." I read a strong claim for reasonably equitable sharing*, and I do not consider the long documented 1:8 split observed at very short RTTs as fair coexistence, do you? > On Feb 26, 2020, at 13:30, alex.burr@ealdwulf.org.uk wrote: > > Sebastian, > > > On Tuesday, February 25, 2020, 6:39:08 PM GMT, Sebastian Moeller <moeller0@gmx.de> wrote: > >> the short answer to the question " why you keep on saying/repeating that DualQ is broken" is. Because the class isolation component of this AQM is considerably >> worse than the state of the art. > > [AB] I believe there is some confusion here. AFAICT the L4S AQM does not have a class isolation component in the sense you are talking about. > My understanding is: > - Today, in single queue bottlenecks, flows cooperate to split the bandwidth. > - FQ systems render this unnecessary by deciding in the network the bandwidth allocated to all flows. > - L4S has a goal of extending the existing 'cooperate to split the bottleneck bandwidth ' system to flows which use different congestion signalling mechanisms. [SM] That does not match the claim from the abstract cited above about "reasonably fair coexistence". And more to the point, in a two class view of the world, as has been demonstrated equitable sharing between classes does not require cooperation of the two classes (see https://l4s.cablelabs.com/l4s-testing/key_plots/batch-l4s-s2-2-cubic-vs-prague-50Mbit-0ms_var.png versus https://l4s.cablelabs.com/l4s-testing/key_plots/batch-l4s-s1-2-cubic-vs-prague-50Mbit-0ms_var.png). My argument then is, if one insists upon voluntarily adding a coupling between the classes, then this coupling should not introduce undesired and unintended side-effects. > > In order to cooperate, the flows cannot be isolated. [SM] But cooperation is not mandated by anything and not a goal in itself? The goal IMHO is reasonably fair coexistence and if cooperation and coupling do not achieve this, they are not the proper solutions for the problem at hand. > > There is some verbiage about 'latency isolation' in the L4S drafts, which may be the source of this confusion. [SM] That is not something I am arguing against, I am really talking about the goal of "reasonably fair coexistence" in https://tools.ietf.org/html/draft-ietf-tsvwg-l4s-arch-05 and from https://tools.ietf.org/html/draft-ietf-tsvwg-aqm-dualq-coupled-10 "This specification defines `DualQ Coupled Active Queue Management (AQM)', which enables these Scalable congestion controls to safely co-exist with Classic Internet traffic. Analytical study and implementation testing of the Coupled AQM have shown that Scalable and Classic flows competing under similar conditions run at roughly the same rate." I do not believe that I am confused when I argue for measuring L4S's AQM of choice against its own claims, and I also believe that a ratio of 1:8 falls well out of being "roughly the same rate". > > It seems to me that arguing about isolation as if it were an agreed requirement has been the source of much unnecessary frustration on both sides. [SM] I still believe that the goal "reasonably fair coexistence" is not only agreed upon by all, but also that this is a condition sine qua non for considering larger deployment of L4S nodes into the internet (aka the experiment). It is well possible that the IETF consensus will fall differently, but it was quite clear to me that the actual facts about dualQ's failure mode were and are not widely recognized by the IETF members, and so my main goal is ot raise awareness of the issue as well as argue for strict isolation as requirement for the L4S drafts to proceed (knowing full well, that this is not my decision to make). > It is legitimate to a) advocate for flow or class isolation, or b) to point out circumstances in which L4S has not achieved the cooperation which is is claiming. But I do not see that the WG has, at the time of writing, already decided that class isolation is a requirement [SM] I hope by now you understand that the isolation I harp about is not a new requirement I made up, but rather a claim about how L4S operates taken from the L4S rfc drafts, all I am doing is pointing out that the dualQ coupled AQM as currently implemented falls short at achieving that goal. But I also subscribe to the notion that when releasing a known problematic protocol into the internet strong safety requirements are in order. > for allowing new congestion signalling mechanisms onto the internet. [SM] Good point! The rationale for requiring strict isolation is not that L4S defines a new "congestion signaling mechanism" but that it does so in a non-backward compatible fashion that unless isolated will starve non-L4S traffic. It is the clear and present danger (as demonstrated) for starvation that IMHO justifies a requirement for sufficiently strict isolation, not the new signaling method in itself As an example the SCE proposal offers a very similar 1/p-type congestion signaling mechanism, that is fully backward compatible and will not starve non-SCE traffic. > For example, I do not see this specified in rfc4774. [SM] https://tools.ietf.org/html/rfc4774#page-11 section 5.2 Coexistence with Competing Traffic seems relevant here: "A second general issue concerns the coexistence of alternate-ECN traffic with competing traffic along the path, in a clean environment where all routers understand and are willing to use the alternate ECN semantics for the traffic that specifies its use. If the traffic using the alternate ECN semantics is best-effort traffic, then it is subject to the general requirement of fair competition with TCP and other traffic along the path [RFC2914]." https://tools.ietf.org/html/rfc2914: section 3.2. Fairness says "In addition to a concern about congestion collapse, there is a concern about `fairness' for best-effort traffic. Because TCP "backs off" during congestion, a large number of TCP connections can share a single, congested link in such a way that bandwidth is shared reasonably equitably among similarly situated flows." I think that strict isolation between classes is the most reliable and robust method to meet rfc4774 section 5.2 requirement of "of fair competition with TCP". How do you interpret this? But independent of whether isolation is a requirement a a consequence of existing in-force RFCs, do you really consider it a good idea and proper engineering practice to release a know biased/unfair AQM into wild when it has been demonstrated that much lower levels of bias/unfairness are well achievable? > Perhaps I have missed something, but for this to be a requirement, I think you need to convince the WG. [SM] Yes, indeed, it seems I need to do a better job in that regard. Sebastian > > Alex > > > > > > Please compare https://l4s.cablelabs.com/l4s-testing/key_plots/batch-l4s-s1-2-cubic-vs-prague-50Mbit-0ms_var.png (dualQ @ 0ms added RTT, throughput ratio ~1:8) with https://l4s.cablelabs.com/l4s-testing/key_plots/batch-l4s-s2-2-cubic-vs-prague-50Mbit-0ms_var.png (fq_codel @ 0ms added RTT, throughput ratio ~1:1). Note how dialQ performs catastrophically worse than fq_codel under otherwise similar conditions. With just two flows (one TCP Prague and one cubic), fq_codel here acts as a per-class-fair AQM, perfectly sharing the bottleneck bandwidth between the two flows/classes. That is what I consider the state of the art. > I hope that if the L4S team deploys an AQM on the internet that this will not regress in comparison what is achievable and already out there. > Before somebody is going to misunderstand the point I am making here. I am NOT proposing you use fq_codel or flow queueing in general, but I do propose that you use an isolation mechanisms between your two traffic classes that is at least as robust and reliable as fq_codel's. As far as I can tell this level of isolation is a solved problem and not getting close to that is something I consider to be a deficit or brokenness. > > > > > >> On Feb 25, 2020, at 17:46, De Schepper, Koen (Nokia - BE/Antwerp) <koen.de_schepper@nokia-bell-labs.com> wrote: >> >> Hi Sebastian, >> >> What I showed in the demo is what you called below B). > > [SM] Thanks for clearing this up. > >> It was a convenient play-example to easily show that we can fully control the RTT-function f(). It compensates the 15 ms extra latency that classic flows gets by needing a bigger queue. So f()=RTT+15ms, making both Prague and classic flows getting exactly the same rate if they have the same base RTT. It is not our recommended f(), it was just simple to show. > > [SM] Okay, as I said it is a nice hack to support the hypothesis that dualQ's isolation method is insufficiently strict. > >> >> If you want A) you need the following f()=max(15ms, RTT), meaning that any flow behaves as a 15ms flow (if it's real RTT is not bigger than 15ms). > > > [SM] It is not so much that I "want" A) but that you promised A), by calling this RTT-independence... > >> We haven't tested RTT independence for flows with a larger real RTT than the target RTT. >> We'll leave that up to others to further test/improve the throughput for higher RTTs (which everyone seems to accept). >> >> >> The following plot shows for A) where f()=max(15ms, RTT), the throughput for different 2-flow RTT-mixes (similar as in the paper you referred to): >> https://l4steam.github.io/40Mbps%20RTT-mix%20Prague-RTT-indep.png > > [SM] Thanks, appreciated. > >> As you can see on the left half, flows below 15ms become RTT independent (get the same rate), and on the right half, lower than 15ms RTT flows are limited pushing away higher RTT flows (100ms here) up to one comparable to a 15ms flow. > > [SM] Yes I see. Calling that "RTT-independence" is a bit of a stretch though, no? > >> >> Our implementation has currently both implemented as an option plus one extra proposal function that Bob provided (gradual changing - with a limited RTT independent for the lower RTTs). More on that later. > > [SM] So don't get me wrong, according to your slides the requirement "Reduce RTT dependence" has the status "evaluat'n in progress" how about you share the data/slides that you already have (like the figure above)? That would allow a considerably more data-driven discussion. > > >> >> To be clear we don't propose B), rather something A)-like with a bit lower target RTT (5ms?) that still gives benefits for lower RTTs, but also limited like Bob proposed. > > [SM] My problem with this approach is not necessarily the fact that plugging the 15ms number from the non-LL-queues AQM at some other place to undo its damage. But the fact that this other place is completely outside the node that will actually run the L4S-aware AQM. It is fine IMHO to have endpoint protocols to work with heuristics and approximations to deal with the existing internet, but I really wonder whether the need to modify a not-deployed-yet and un-finished protocol to make up for avoidable design decisions for a not-deployed-yet and un-finished AQM might not indicate that something is off. > >> >> Other possible solutions are: >> - have the Classic AQM target at 1ms too > > [SM] Which will work great for RTTs in the 10-50ms range but will cause utilization issues at higher yet still realistically common RTTs, the reason why I keep asking for a test with 5ms is that this with Codel and Pie works reasonably well ven for true RTTs in the >= 200ms range. > >> - have a bigger coupling factor > > [SM] Will that actually solve the problem though? My intuition tells me that this will just shift the conditions around under which LL pummels non-LL traffic. > >> - make classic TCP RTT independent in the higher RTT range > > [SM] Not a viable option, we need to work with the already deployed TCPs reasonably equitable. This was in jest, surely? > >> - FQ > > [SM] Don't get carried away, in your case all you need is fairly distribute between two classes queues, you could still call this "fair" queueing if referring to fairness between classes but CQ, class queuing might also be a less contentious name for it,. IMHO that a limited two class strict fairness scheduler is the proper solution, but I do not claim that there are not better fitting solutions around that achieve a similar robust and reliable isolation between the two traffic classes L4S considers. > >> - provide RTT info in the packet header > > [SM] Theoretically a nice idea, but will not help with the existing internet much. > >> - ... >> but I don't think people will in general favor these... but if possible they are still usable. > > [SM] Well, the two class fair queueing option seems like a winner to me. > >> >> I don't understand why you keep on saying/repeating that DualQ is broken. > > [SM] If a new solution to an old problem falls well behind the current state of the art, I consider the design of the new solution in that specific dimension to be insufficient or defective. > > >> DualQ wants to reduce the latency for L4S, but it cannot do the same for Classic, because of limitations of Classic congestion control itself. > > [SM] Fair enough, but the way you implemented that feature is by also giving L4S a massive "bandwidth" advantage and that is not how you frame and sell the whole L4S idea in the first place. > >> We don't make Classic traffic RTT dependent, it is already RTT dependent, and has been since the beginning of congestion control. > > [SM] And it will stay RTT dependent just as TCP Prague will retain at least a residual RTT dependence, since shorter control loops are nimbler than longer ones, and the only general available option (make all congestion controller behave as if behind the maximum possible RTT) is clearly not suited for anything but Gedankenexperimente. > > >> So my conclusion is that the problem is with TCP congestion control that is RTT dependent and Classic that is not happy with a short queue. How do you suggest to solve this other than making TCP less RTT dependent??? > > [SM] Use something like DRR++ to schedule packets from the two queues you still use to separate 1/p-type traffic from 1/sqrt(p)-type traffic, Use what ever classifier you want* to steer packets in one of the queues, and instantiate your two differential marking regimes depending on the traffic's type, that should solve most of the issues right there. The scheduler will make sure both queues share the egress traffic equitable and the rest just stays as is in you L4S design, except you might be able to abandon the cute but only approximate coupling idea** and deduce each queue's marking rate directly from its occupancy level/sojourn time. > Now, this will solve the particular issue I a concerned about, backward compatibility and equitable sharing with existing traffic***. It might well fall short to meet some of your design goals and requirements, I would appreciate if you could describe how and why the proposed scheme would not work for L4S? > > Regards > Sebastian > > *) Actually I would strongly recommend to use a DSCP for the required marking, at least in addition to what ever else you end up picking. > **) If coupling would solve the issue we would not have this discussion... > ***) I note that until L4S actually drives 50% of internet traffic equitable sharing is already giving a strong bandwidth bias towards L4S at bottleneck links. That is something I am not happy with, but not something I have a better solution for that you will find acceptable. > > > > > >> >> Regards, >> Koen. >> >> -----Original Message----- >> From: tsvwg <tsvwg-bounces@ietf.org> On Behalf Of Sebastian Moeller >> Sent: Friday, February 21, 2020 9:00 AM >> To: tsvwg IETF list <tsvwg@ietf.org> >> Subject: [tsvwg] Todays Meeting material for RTT-independence in TCP Prague >> >> Dear All, >> >> >> after today's virtual meeting I am still pondering Koen's RTT-independence day presentation. The more I am thinking about this the more confused I get about what was actually achieved. >> >> Was it: >> A) true RTT independence between TCP Prague flows so flows of wildly differing RTTs will share an L4S AQM's LL queue fairly? >> >> B) class RTT independence, that is adding the so far under-explained 15 ms target for L4S's non-LL queue to the internal RTT response generation in TCP Prague (which, let me be frank would be a gross hack and solving the right problem (dualQ's failure to meet its goals robustly and reliably) at the wrong position)? >> >> C) all of the above? >> >> I had a look at the slides, and all I see is B) and no data for A), and IIRC the demo also focused on B), dod I miss something. If you have data for A) please share with us, because B) alone is not well-described with the RTT-independence moniker. >> >> Question: is it just me, or do others also get uneasy when a yet un-deployed transport protocol modification (TCP Prague) grows a magic +14.5ms constant somewhere in its innards to work-around the existence of another under-explained 15ms constant somewhere in the innards of another yet un-deployed AQM, INSTEAD of simply fixing said un-deployed AQM to not require such and ugly hack in the first place? Are all L4S compliant transports expected to grow the same ~15ms constant? >> What if in the future the dualQ AQM is superceded by something else, that for good justification* wants to implement a target of 5ms, do you envision all modified transport protocols to be changed?** >> >> >> The fact of the matter is, the dual queue coupled AQM as currently implemented is broken, but I see >> >> >> The rationale why the magic f() would have been added to TCP Prague without the need to paper over dualQ's major failure was a bit thin in Koen's presentation, so please supply me with more reasons why this is a good idea and not simply the cheapest way to paper over dualQ brokeness without actual real engineering to fix the root cause? >> >> Also, please show how these modifications make bandwidth sharing inside the LL-queue more equitable and significantly less RTT-dependent, ideally by using a similar mix of flows like in The Good, the Bad and the WiFi: Modern AQMs in a residential setting: T.Høiland-Jørgensen, P. Hurtig, A. Brunstrom: https://www.sciencedirect.com/science/article/pii/S1389128615002479, so that your results can be compared to figure 6. Until that point I will assume that increased RTT-independence is still aspirational. >> >> Best Regards >> Sebastian >> >> >> >> *) I note again, that the CODEL RFC has a section that gives some rational why 5ms is a reasonable target value for flows in the 20-200ms RTT range, and that the PIE proponents have not presented any clear study demonstrating that the chosen 15ms is optimal in any dimension, which would be interesting as DCSIS-PIE actually seems to default to 10ms... >> >> >> **) This is another sticking point, I have asked the L4S team repeatedly to use their test-bed (which should make testing different configurations a breeze), to measure between-class fairness and link-utilization between the LL- and the non-LL queues for short medium and long RTTs with the non-LL-queues target set to 5ms. >> And so far all I hear is something along the lines of, if that interests me, I could do my own tests. My interpretation is that either the test bed is far less flexible and easy to use, or there is the fear that the 5ms data would reveal something unpleasant? >> >> >>
{kind=link}
{kind=link}
{kind=link}
- [tsvwg] Todays Meeting material for RTT-independe… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… De Schepper, Koen (Nokia - BE/Antwerp)
- Re: [tsvwg] Todays Meeting material for RTT-indep… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… alex.burr@ealdwulf.org.uk
- Re: [tsvwg] Todays Meeting material for RTT-indep… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… Greg White
- Re: [tsvwg] Todays Meeting material for RTT-indep… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… De Schepper, Koen (Nokia - BE/Antwerp)
- Re: [tsvwg] Todays Meeting material for RTT-indep… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… De Schepper, Koen (Nokia - BE/Antwerp)
- Re: [tsvwg] Todays Meeting material for RTT-indep… Sebastian Moeller
- Re: [tsvwg] Todays Meeting material for RTT-indep… Rodney W. Grimes